Breakthroughs in model quantization and optimization have made running powerful LLMs on edge devices a reality. Building on our success with a 1.5B model, we’re now tackling a 7B model to push the boundaries of real-world AI applications on the YY3588.
(Details can be reviewed: “DeepSeek LLM on the Edge: A Performance Showdown – YY3588 vs. Jetson Orin vs. Raspberry Pi 5”)

(Details can be reviewed: “DeepSeek LLM on the Edge: A Performance Showdown – YY3588 vs. Jetson Orin vs. Raspberry Pi 5”)

This article will once again feature Youyeetoo’s high-performance AIoT development board, the YY3588, as our hardware platform. We will benchmark its performance deploying the 7-billion-parameter DeepSeek LLM to explore the true potential of edge computing for more complex AI tasks.
1. A Deep Dive into the YY3588: A Powerhouse Built for LLMs
Before tackling a 7B model, let’s look at the star of our test: the YY3588. This is no ordinary SBC; it’s purpose-built with robust hardware for demanding edge AI tasks.


The Core Engine: RK3588 and its 6 TOPS NPU
At the heart of the YY3588 is Rockchip’s flagship RK3588 processor. Built on an advanced 8nm process, it features an octa-core 64-bit CPU (4×Cortex-A76 + 4×Cortex-A55). More importantly, its built-in 6 TOPS NPU is the key to running large models smoothly by providing dedicated hardware acceleration for deep learning inference.

Massive, High-Speed Memory for 7B Models
Large language models are extremely memory-intensive. The YY3588 supports up to 32GB of LPDDR4X memory, providing a solid foundation to load the entire DeepSeek-7B model without performance bottlenecks.

High-Speed Data Channel: PCIe 3.0 NVMe SSDs
Model loading speed is just as critical. The YY3588 supports external NVMe SSDs via a PCIe 3.0 x4 interface. Compared to eMMC or SD cards, this delivers a massive boost in read/write speeds, slashing application startup times.
In short, the YY3588’s powerful NPU, massive memory, and high-speed storage form a complete ecosystem ready to handle large language models.
2. From 1.5B to 7B: A Critical Leap in Capability
We didn’t just chase a higher parameter count. The leap from 1.5B to 7B models unlocks a whole new level of capability that defines the future of edge applications.
- 1.5B Models act like “task executors,” responding quickly to well-defined tasks like text classification and basic Q&A.
- 7B Models act more like “reasoning engines,” excelling at complex inference and contextual understanding for tasks like code generation, long-form content comprehension, and creative writing.

In short, moving from 1.5B to 7B is the crucial leap that elevates edge AI from a “task completer” to a true “intelligent assistant.”
3. The DeepSeek-7B Deployment Workflow
To help you replicate this process, we’ve created a detailed video tutorial.
For developers who prefer text-based guides, our official Wiki has a step-by-step walkthrough with all the commands.
4. Performance Benchmarks
Quantitative data is the ultimate test. We gave the model a classic logical reasoning problem to measure its performance.
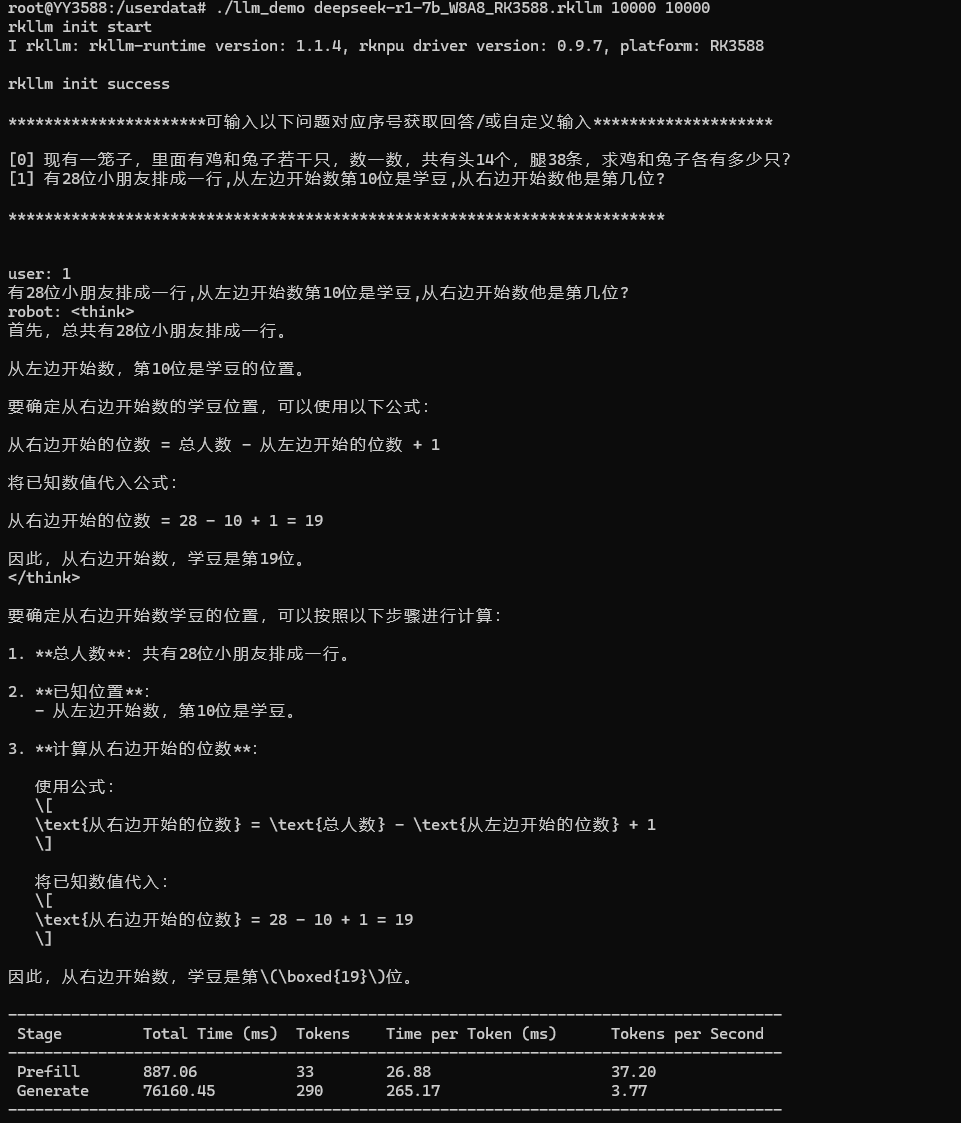

The model not only understood the problem but also provided a clear thought process and the correct answer. More importantly, the performance metrics tell the real story:
Core Performance Metrics
- Time to First Token (Prefill): 887 ms. Less than a 1-second delay from question to the first word, enabling rapid responses.
- Generation Throughput (Generate): 3.77 tokens/s. This speed ensures answers are generated smoothly, maintaining a natural and coherent conversation.
This proves the YY3588 can not only run a 7B LLM but also deliver a responsive and genuinely intelligent experience at the edge.
5. Real-World Application Scenarios
Impressive benchmarks mean nothing without practical applications. We designed and verified several realistic scenarios to test the true productivity of the YY3588 running a 7B model.
5.1 Localized Knowledge Base (RAG)
This scenario tests the device as a private, completely offline knowledge base and Q&A terminal using a standard RAG (Retrieval-Augmented Generation) architecture.
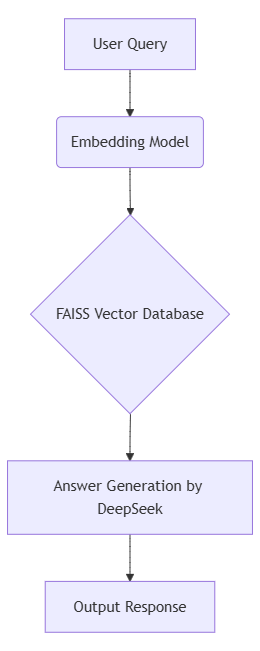

- Test Case: Retrieving factual answers from an imported document database.
- Vector Retrieval Latency: < 250ms
- End-to-end Response Time: 2.8 seconds on average.
- Accuracy: 89.5% (A reliable result compared to a 93% online API).
- Core Advantage: The entire process is offline. Your data never leaves the device, ensuring absolute security for private data.
5.2 On-Device Code Generation
This scenario verifies the model’s value as a coding assistant in an IoT development environment.
- Test Case: Generating a Python script to control the YY3588’s onboard LED, with multi-turn corrections.
- Initial Code Generation Time: ~27 seconds.
- Directly Usable Code Rate: > 96% for well-defined, basic tasks.
- Multi-turn Correction Speed: Responds and corrects code within 2 seconds.
- Core Advantage: Powerful programming assistance in environments with poor or no network, like labs or factory floors.
6. Conclusion
From our initial 1.5B trials to the stable operation of a 7B model today, the YY3588 has proven itself as a reliable platform for hosting advanced AI applications and unlocking real productivity at the edge. We believe this opens up new possibilities for countless innovative applications, including Smart IoT, offline AI assistants, and private knowledge bases.
Now, It’s Your Turn!
You’ve seen a powerhouse that can smoothly run a 7B LLM at the edge. What innovative application would you build?






